自 2023 年推出 AI Overviews(原稱 SGE)以來,Google 搜尋逐步從傳統的連結列表轉向以生成式 AI 為核心的「答案引擎」模式。2025 年 3 月宣布 AI Mode,目前已在美國全面推出(筆者註:台灣也已正式推出 AI Overviews,但 AI Mode 可能還要等等),成為搜尋體驗中的中樞功能。
AI Overviews 已觸及超過 15 億用戶月次使用量。儘管可即時提供精準概覽,但也帶來製造廣告曝光的新管道,Google 已開始測試在 AI 回答中放置贊助內容( AI Overviews、AI Mode )。
隨著這股浪潮湧入,所有內容創作者與行銷人必須重新思考 SEO 策略:除了關鍵字排名,還須讓內容在 AI 生成回應中獲得優勢曝光。
Google AI 搜尋如何影響 SEO ,該如何面對?(中文播客)
理解 Google 的 AI 搜尋架構與動機
AI Mode vs AI Overviews:兩種不同的曝光場域
AI Overviews:由 Gemini 模型生成摘要回覆,並附帶多個來源連結,用於快速解答常見查詢。
AI Mode:更進階的對話式搜尋體驗,支援深入追問、多步推理及多模態輸入,並與 Gmail、地圖等產品串連。
Google 的 AI 內容整合目標
提升使用者黏著度與廣告效益
維持競爭優勢
平衡內容創作者利益
SEO 最佳化策略:在 AI 搜尋中脫穎而出
方法一:建立卓越 E‑E‑A‑T 架構,讓 Google AI「可信」
Google 強調 E‑E‑A‑T 原則( Experience, Expertise, Authoritativeness, Trustworthiness )是 AI 判斷內容可信度與引用建議的核心。
實務建議
提供實際案例分享、操作紀錄、客戶見證
作者需具備領域資歷
引用具公信力的網站
公開資料來源與研究報告
方法二:內容結構設計迎合生成式摘要框架
AI 回答常使用:
簡潔開頭摘要
條列或標題式分段
深度解說中段
資料來源引用
實務建議
開頭明確解題(40‑60字內摘要)
使用H2/H3條列分段
每段聚焦單一主題
加粗重要句子
明確引用出處(即使不外顯)
方法三:技術層面強化—Robots 標記與結構化數據
Google 提供內容控制技術以協助管理 AI 顯示範圍。
實務建議
使用 indexifembedded 控制 AI 可見性
避免 robots.txt 阻止重要內容
使用結構化數據 Schema:FAQ、HowTo、Article、Breadcrumb 等
方法四:保持內容更新與時效性
AI 對資訊時效性的要求提高,過時內容將降低顯示概率。
實務建議
為內容加註發布與更新時間
定期回顧與修訂老舊文章
標示版本與修改紀錄
方法五:多模態資料內容提升抓取價值
Google AI Mode 支援圖片、影片、表格等多媒體分析。
實務建議
圖片加 alt 屬性與說明
影片加 Rich Snippet、時間戳、上傳者資訊
表格標示 Dataset 結構與 caption
方法六:優化追問體驗,提升對話串留存機率
AI Mode 支援連續追問,讓內容可被反覆引用。
實務建議
設計 FAQ 形式的追問清單
每段末尾加入引導語句
建立話題導覽索引表
方法七:避免 AI 回應中的幻覺( hallucination )
錯誤答案會傷害信任感與網站公信力。
實務建議
明確標示資料來源
避免模糊語句(如:「研究顯示」)
提供可驗證原始資料(PDF、數據集)
方法八:主動監控與測試內容效果
Google 提供工具讓站長檢測內容在 AI 搜尋的表現。
實務建議
使用 Search Console 觀察 AI Overviews 表現
使用 URL Inspection API 驗證可抓取性
比對內容優化前後曝光差異
全方位策略總覽表格
目標維度
操作要點
E‑E‑A‑T 強化
作者資訊、專業資格、權威來源、真實案例
結構化內容設計
摘要段落、分段標題、粗體重點、FAQ 結構
技術 SEO 優化
Robots 標籤、indexifembedded、Schema 應用
資訊新鮮度
加註時間、內容更新、版本紀錄
多模態支援
alt 圖片、Rich Snippet 影片、Dataset 表格
防範幻覺
資料明示、避免模糊句、公開來源
追問路徑設計
FAQ 延伸、話題導覽、層層鋪陳
成效監控
Search Console、API 工具、效果 A/B 測試
前瞻觀察與應對策略
趨勢一:AI 回答插入廣告機會增多
未來將進一步擴大 AI 中的贊助內容展現。
建議:結合關鍵字廣告與原創內容設計,提高流量轉化。
趨勢二:出版商爭取補償與授權
內容授權制度可能成為 Google 後續政策方向。
建議:評估是否提供授權或 opt-out 控制權,提前準備應對機制。
趨勢三:多模態搜尋權重提升
圖片與影片搜尋比重增高。
建議:增設圖表與影片資產,並強化語意與結構標示。
趨勢四:訊息來源「接地性( Grounding )」逐步開放控制
未來可能開放 Grounding API 控制來源資料。
建議:預研 API 使用條件與內容曝光原則,規劃私有來源保護策略。
結語
Google AI 模式帶來前所未有的挑戰與機會。內容創作者若能掌握:
AI 上的語意結構規則
E‑E‑A‑T 的實踐方式
技術與內容雙向優化
便能在這場內容競爭中穩占一席。生成式 AI 搜尋的未來,仍可由創作者主導──前提是懂得如何與 AI 共存,並讓它替你說話。
此人事震盪迅速引發政治爭議和法律界關注。美國國會眾議院行政委員會民主黨首席議員喬·莫雷爾 ( Joe Morelle ) 發表嚴厲聲明,痛批川普解雇珀爾穆特是「無恥且前所未有、毫無法律依據的權力攫取」。莫雷爾指出,川普在珀爾穆特拒絕為伊隆·馬斯克 ( Elon Musk ) 大規模挖掘版權作品訓練 AI 模型的企圖背書後不到一天就將其開除,絕非巧合。事實上,莫雷爾的聲明直接連結了版權局當週發布的 AI 報告預印版本,暗示珀爾穆特因報告內容觸怒了總統及其盟友馬斯克。美國民主黨人普遍認為,此舉嚴重破壞了版權局等獨立機構的專業自主性,是政治力量干預文化及法律機構的危險先例。莫雷爾更警告,罷免版權局長的行動「再次踐踏了憲法第一條賦予國會的權力,並使價值數兆美元的產業陷入混亂」。
另一方面,川普政府人士則給出不同說法。白宮發言人卡羅琳·萊維特 ( Karoline Leavitt ) 在解職國會圖書館館長海登時,指稱海登推行了某些「令人擔憂的事項」,例如倡導多元包容政策、在圖書館為兒童提供不當讀物等,但未提出實質證據。對於版權局長的人事異動,白宮尚未正式說明理由。川普本人則在社群平台 Truth Social 上轉發了保守派律師麥克·戴維斯 ( Mike Davis ) 的相關評論。該評論似乎對開除珀爾穆特持批評態度,指出:「現在科技界將嘗試為 AI 牟利而竊取創作者的版權,這絕對不可接受。」川普轉發了這則評論,未直接闡述自己的立場。戴維斯是川普的支持者,有傳聞稱可能出任其司法部長,他的發言令人困惑地反對此次解職行動,暗示移除珀爾穆特反而會放任科技業者濫用版權內容。這些互相矛盾的訊息讓外界更難以釐清川普政府此舉的官方理據。觀察人士擔憂,版權政策決策的獨立性已被政治算計侵蝕。
與馬斯克的 xAI 及 AI 業界利益掛勾?
珀爾穆特被炒魷魚的時機與報告內容,使不少人將矛頭指向川普的科技盟友,尤其是馬斯克。伊隆·馬斯克不僅是社群平台 X 的擁有者,近年來更投入創立 AI 新創公司 xAI,積極進軍大型生成式 AI 模型領域。馬斯克近期曾在 X 平台上公開表示支持「廢除所有智慧財產法」,對現行版權與專利制度表達強烈不滿。2025 年 2 月,他甚至曾嘗試收購 OpenAI ,但提案未果。種種跡象顯示,馬斯克傾向讓 AI 研發不受傳統版權框架束縛,以獲取海量數據優勢。
馬斯克與川普關係密切,外界普遍認為兩人在政策理念上有共鳴。馬斯克被視為川普的盟友,雙方在科技產業上的利益有交集。川普重返白宮後,高調宣示推動美國 AI 產業發展:他在上任伊始即宣布一項由 OpenAI、軟銀和 Oracle 參與的公私合營計畫,承諾動員高達 5,000 億美元資金興建 AI 基礎設施。此舉表明川普政府與主要 AI 企業之間形成緊密合作關係,共同加速 AI 技術部署。在這背景下,版權局報告對 AI 訓練資料合法性的質疑,等同潑了科技巨頭一盆冷水,被視為對矽谷利益的直接挑戰。該報告認定,大規模商業抓取受保護內容訓練 AI 可能逾越「公平使用」界線,這無疑威脅了包括馬斯克 xAI 在內的所有 AI 業者現行做法的合法性。
值得注意的是,AI 產業一直面臨來自版權方的法律戰。近年已有多起作家、藝術家控告 AI 公司的官司陸續出現:例如 2023 年包含約翰·葛里遜 ( John Grisham )、喬治·R·R·馬丁 ( George R.R. Martin ) 等著名小說家在內的多位作者,對 OpenAI 等公司提出集體訴訟,指控其在未經許可下擅自抓取作者作品來訓練 GPT 模型,構成版權侵權。類似地,藝廊及攝影機構也控告生成式 AI 模型非法使用受保護影像訓練 ( 如 Getty Images 控告 Stability AI )。這些法律爭端關鍵就在於 AI 模型訓練期間對既有作品的使用是否侵犯版權。版權局的報告顯然傾向於保護著作權人利益,暗示許多商業 AI 應尋求授權而非單方面抓取內容。這與 AI 公司的利益相左,也與馬斯克等人鼓吹的「開放數據」理念相衝。莫雷爾等民主黨人因此質疑,川普火速拔除珀爾穆特,意在替馬斯克的 xAI 等業者清除法律障礙。若版權局長之位由對 AI 產業更友善的人選取代,未來官方報告或政策方向可能出現逆轉,改為偏袒 AI 公司立場。
排除法律阻力的手段?
川普解雇珀爾穆特是否真是為了替 AI 業者解除掣肘? 綜合多方資訊,時間點與相關言行提供了一定暗示。首先,解職決定緊隨報告發布,耐人尋味。科羅拉多大學法學教授布萊克·雷德 ( Blake Reid ) 即評論稱,這份報告對 AI 公司而言是「全面的敗局」,版權局可能意識到自身將遭清洗,因而急於在離任前公開研究結果。換言之,珀爾穆特的團隊或許早已感受到政治壓力,提高警覺並搶先亮出專業觀點,即使得罪強權也要對外發聲。莫雷爾對解職動機的推測進一步強化了這種觀點—他直接點名馬斯克,顯示民主黨陣營深信這是川普政府服務特定企業利益的舉措。
其次,川普本人體現出對 AI 產業高度積極的支持態度,而對於智慧財產權的態度則相對淡漠甚或反向而行。他在任期伊始投入巨資聯合 OpenAI 等公司,強化美國 AI 實力。相較之下,並未見到川普對保護創作者版權有類似熱忱。馬斯克呼籲廢除 IP 法令的論調,更獲川普在網路上的附和互動。這種政策取向暗示,在川普政府眼中,版權等法律障礙不應擋在 AI 發展之前。取而代之的可能是讓路給企業,事後再看情況調整。解雇發聲持異議的官員,正符合這樣的作風。
不過,也有法律專家對過度簡化此舉的動機提出質疑。公共知識組織 ( Public Knowledge ) 法律顧問梅雷迪思·羅斯 ( Meredith Rose ) 指出,版權局這份長達 113 頁的報告其實內容審慎,「基本上都在說『視情況而定』」。如果真有人僅因報告結論就要求開除珀爾穆特,「無論立場為何,那人一定是徹頭徹尾的瘋子」。換言之,在羅斯看來,報告雖對 AI 公司不利但稱不上激進,直接開鍘難謂理性舉措。這暗示川普撤換珀爾穆特可能還摻雜其他因素,例如單純的人事權力展示、對前朝官員的不信任,或對版權局長先前某些作為的不滿等。然而直到目前,白宮方面都未給出任何正式說明來澄清原因。因此,從外部觀察者角度,此舉最合理的解讀仍然與 AI 版權爭議和利益輸送脫不了關係。正如新聞網站 TechCrunch 分析所言,此事件凸顯出 AI 技術、創作者權益與政治力量間日益緊張的角力。川普政府以強硬手段調整版權管理高層,極可能意在塑造一個對 AI 企業更友善、阻力更少的法律環境。
AI 創作版權未來走向與國際連鎖效應
珀爾穆特的去職為美國 AI 與版權政策投下變數,未來影響將在國內外逐漸顯現。在美國國內,短期內版權局的政策方向勢將出現轉折。新版權局長的人選若由川普政府指派,預期將更傾向保護 AI 產業利益,而在版權問題上採取較寬鬆甚至縱容的態度。先前在珀爾穆特領導下,版權局曾明確重申「具人類創意才能受版權保護」的原則,拒絕為純機器生成內容註冊版權。這使得 AI 生成圖像或文章無法取得版權,部分科技公司曾表達不滿。未來,新任局長是否會調整這一立場,引發關注。如果版權局放寬對 AI 生成內容的版權保護,可能鼓勵企業產出更多 AI 作品並申請保護,但也可能削弱傳統版權對人類創作者的激勵,衝擊創意產業生態。
更關鍵的是,AI 模型訓練所涉的大量資料抓取行為,在美國將進入法律灰色地帶。隨著版權主管機關態度軟化,AI 公司可能更加大膽地收集網路文章、書籍、藝術品等作為訓練材料,而不再主動尋求授權。這或許降低了 AI 開發的短期法律風險與成本,等於變相解除一大束縛。但長遠看,訴訟風險仍未消失—最終決定這些爭議的將是法院和國會。如果創作者群體持續透過司法途徑施壓 (如正在進行的多起集體訴訟),法院判決可能為 AI 訓練的版權適用劃出紅線。若司法認定未經授權的訓練構成侵權,AI 業者屆時將面臨更嚴厲的後果。反之,若法院傾向認同某種程度的合理使用,則 AI 公司得利。但無論如何,版權局長的人事變動已讓美國政府在這場辯論中的立場產生動搖。往後拜登政府時期所可能出現的對創作者友善政策,如現在由川普政府逆轉,未來政權再易手時亦可能再度轉向,讓政策環境充滿不確定性。
從國際層面看,美國對 AI 與版權的政策轉變可能引發連鎖效應。各國目前在這議題上態度不一:例如日本早在 2018 年修改著作權法,採取了極為開放的立場,允許 AI 為了資訊分析目的使用任何資料進行訓練,不論商業或非營利,甚至來源是否非法取得都暫不追究。日本政府明確表示,在 AI 發展的追趕階段,對訓練數據的版權限制將不予強制,以利國內 AI 產業迅速成長。這種做法與美國版權局先前報告形成鮮明對比—報告中批評透過非法管道取得內容來訓練 AI 超出公平使用,但日本卻選擇默許類似行為。美國目前尚未立法明確此事,但川普此次的人事干預可能預示美國朝「日本模式」傾斜:即默認 AI 公司大舉蒐集資料,而減少政府介入。反觀歐盟則採取較審慎路線。歐盟在 2019 年《數位單一市場版權指令》中引入了文本與資料挖掘例外規定,但區分用途:非營利科研機構可不經授權進行資料挖掘,商業機構則需尊重版權人設定的 opt-out ( 退出 ) 聲明。如果版權人明確表示不許可,AI 公司不得擅自抓取內容。英國原本一度打算跟進採取更寬鬆的 TDM 例外,允許商業 AI 自由抓取資料,但在創意產業反對下已撤回該提案,轉而尋求產業自律的做法來平衡雙方利益。由此可見,各主要經濟體對 AI 訓練資料版權管制的態度分歧。
在這背景下,美國政府立場的變化將產生跨國影響。如果川普政府放任 AI 公司自由利用受保護內容,可能迫使其他國家也跟進寬鬆,以避免本國 AI 企業處於劣勢,從而引發全球版權保護標準的鬆動。相反地,歐盟等地可能視美國的舉動為警訊,加速制定更嚴格的規範防堵未經授權的資料擷取,或要求 AI 產品在其市場遵守本地版權規則,形成法律衝突與對抗。例如,未來若美國 AI 模型大量吸收歐盟作家的作品,但歐盟法律不承認此種「合理使用」,則相關 AI 產品在歐盟市場可能面臨禁令或責任追究。國際出版商與內容產業也可能聯合施壓,尋求在雙邊協議或多邊場域上要求美方給予創作者更高保障。甚至在未來的貿易談判中,數據挖掘版權例外條款都可能成為爭議焦點:一方著眼於技術發展,自由使用資料;另一方關切創作者權益,要建立跨境保護機制。
對 AI 創作者和科技產業中的版權律師而言,這場風波意味著法律格局的劇烈震盪。AI 創業者可能在短期內得到更寬鬆的資料使用環境,但也須警惕公眾輿論與國內外法規趨勢的反撲。版權律師則需要密切關注政策走向和案例進展,為客戶研擬因應之策。在美國,未來幾年內或將出現立法提案博弈:支持科技業者的一派或許推動立法確認 AI 訓練的「公平使用」地位,減輕法律不確定性;支持創作者的一方則可能提倡建立版權集體授權制度,要求 AI 業者支付版稅以補償內容使用。川普政府目前的舉措傾向前者路線,但其政治壽命未知,政策存在朝令夕改風險。在此同時,AI 技術繼續迅猛發展,創新應用層出不窮,法律框架的滯後與搖擺將使版權相關糾紛成為新常態。
結語
從川普解雇美國版權局長事件可以窺見,AI 時代的版權規則正在被重新書寫。這起事件表面上是人事風波,實則攸關 AI 產業與傳統版權體系的博弈平衡。川普政府強勢介入被視為是替 AI 業者清除障礙的權宜之計,但長遠影響尚難定論。它可能為美國 AI 企業爭取到一時的無拘發展空間,卻也削弱了版權制度對創作者的保護,進而引發更多反作用力。未來幾年,可能會看到美國乃至全球在這場 AI 創新與版權保護的拔河中尋找新的平衡點:無論是透過法院裁決、政策調整或國際協商,各方勢必為定義 AI 創作的版權邊界而持續角力。在此過程中,AI 創作者和版權律師應密切追蹤政策和法規動態,為應對潛在的法律挑戰和機遇做好準備。
If you want to disable optimizations you can type –q 2 (for now). We expect the new default to have better hands so you'll likely prefer it. We also are testing a –q 4 image mode which might have improved coherence and details. More updates to –q 2 and –q 4 coming soon.
Midjourney 於2025年5月2日推出全新「Omni-Reference」功能,標誌著 AI 圖像生成邁入更高精準度與一致性的時代。
Omni-Reference is now live! It's a new way to say "put THIS in my image" for characters, objects, vehicles, and more. Check out the examples or see the full info dump below 👇 pic.twitter.com/NH4PmSIT2A
隨著 Omni-Reference 的推出,Midjourney 朝著更高精度與個性化的 AI 圖像生成邁進,為創作者提供更強大的工具以實現其創意構想。
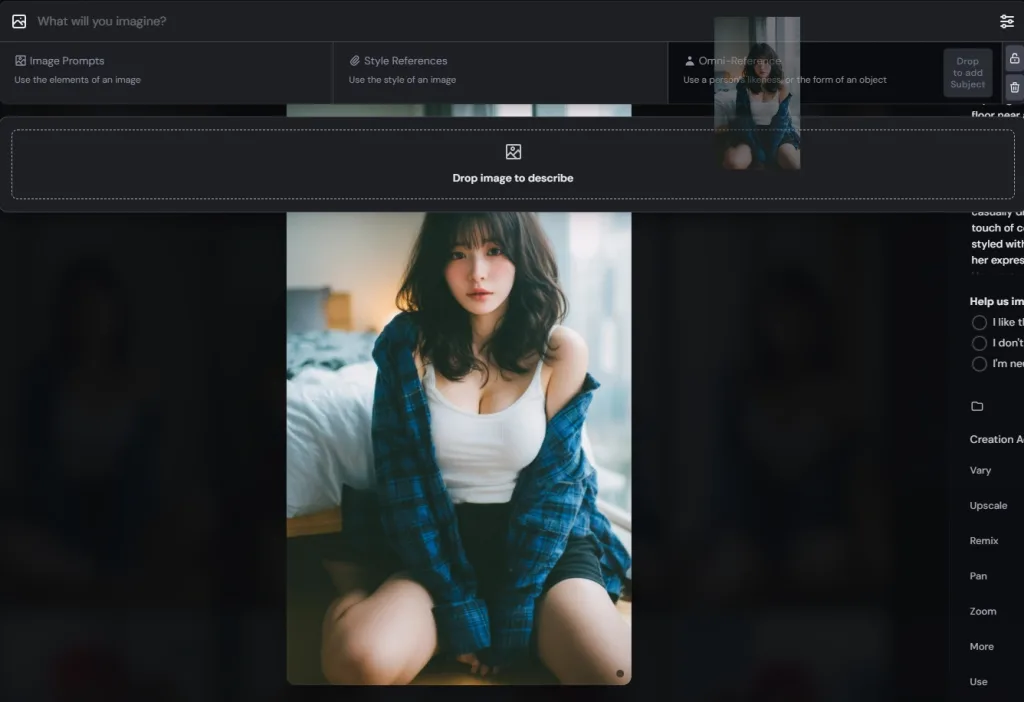
實際測試
先用一張參考圖
將參考圖在 Web 版本上拖拉至指定位置
設定提示詞
這邊我們輸入一個參考提示詞:
An elegant female warrior, with flowing black hair and a soft expression, stands elegantly in front of an abstract background made of thin pink floral silhouettes, like hanging wisteria leaves, in a dynamic pose, one hand on the sword, the other slightly raised, delicate, dreamy lighting, feminine and heroic atmosphere, high resolution, muted tones, central composition. --ar 16:9 --style raw --s 100