
隨著人工智能技術的快速發展,中國 AI 產業正迎來一輪新的競爭高潮。在這場激烈的角逐中,大語言模型(LLM)無疑是最炙手可熱的領域之一。近日,權威第三方評測機構 SuperCLUE 發布了 2024 年 6 月中文大模型評測報告,為我們呈現了一幅生動的中文 AI 大模型全景圖。
排行榜概覽:中國模型迅速追趕,開源黑馬崛起
根據 SuperCLUE 的最新評測結果,OpenAI 的 GPT-4o 以 81 分的絕對優勢繼續領跑全球大模型。然而,中國的頂級模型已將差距縮小至 5% 以內,展現出驚人的進步速度。
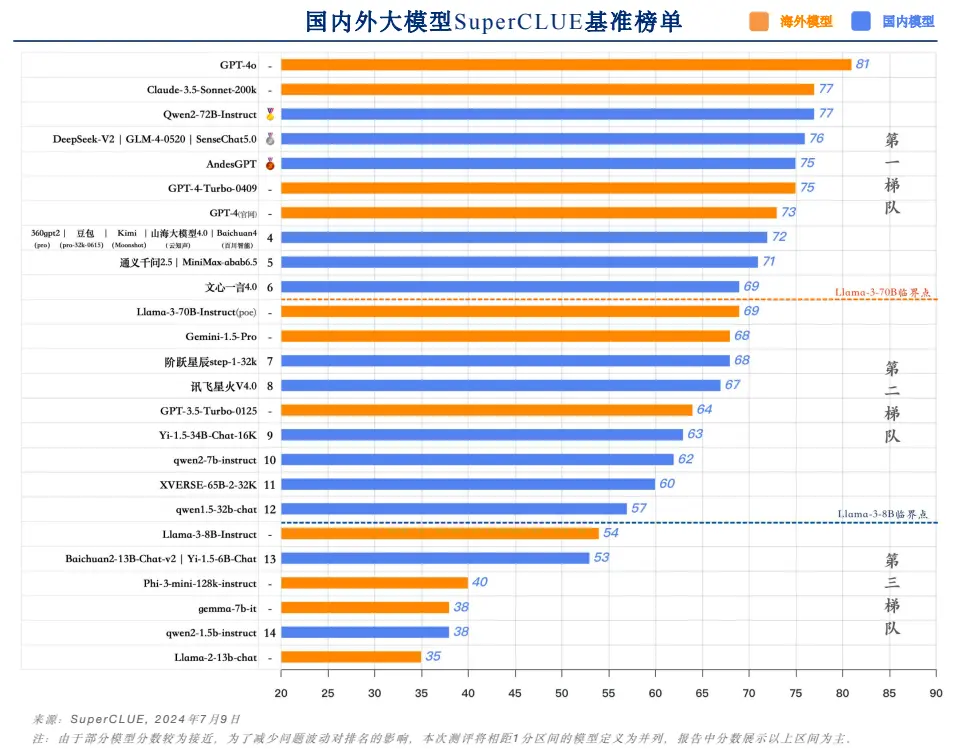
中文大模型基準榜單。資料來源:SuperCLUE
中國大模型市場已然形成了三大梯隊格局。頭部企業憑藉其強大的技術積累和資源優勢,穩居第一梯隊。其中,阿里雲的 Qwen2-72B、商湯科技的 SenseChat5.0 等均以 75+ 的高分位列前茅。緊隨其後的是一批實力強勁的 AI 創業公司,如智譜 AI 的 GLM-4、百川智能的 Baichuan4、月之暗面的 Moonshot (Kimi) 等,它們的表現同樣出色,得分均超過 70 分。
值得特別關注的是,開源模型在本次評測中表現搶眼。阿里雲開源的 Qwen2-72B 不僅力壓眾多國內外閉源模型,更與 Anthropic 的 Claude-3.5 Sonnet 並駕齊驅,與 GPT-4o 的差距僅有 4 分。
重點模型分析:各顯神通,各具特色
Qwen2-72B:阿里雲的開源黑馬
作為本次評測的最大驚喜,Qwen2-72B 展現出全面而均衡的能力。在代碼生成、創意寫作、角色扮演、長文本處理和精確指令遵循等多個關鍵領域,Qwen2-72B 均名列中國第一。此外,它在計算、邏輯推理和工具使用等方面也躋身中國前三。這款開源模型的出色表現,除了證明了中國在 AI 開源領域的實力,也為其他研究者和開發者提供了寶貴的學習資源。
SenseChat5.0:商湯科技的重磅之作
商湯科技的 SenseChat5.0 採用了先進的混合專家架構(MoE),擁有高達 6000 億的參數量,支持 200K 的超長上下文窗口。在本次評測中,SenseChat5.0 展現出均衡的理科和文科能力,尤其在語義理解、代碼生成、角色扮演和創意寫作等方面表現出色。這款模型的綜合實力有目共睹,穩居中國大模型第一梯隊。
GLM-4-0520:智譜 AI 的強勁競爭者
由智譜 AI 和清華大學聯合推出的 GLM-4-0520 是 GLM 系列的最新力作。該模型在創意生成、知識百科、工具使用和精確指令遵循等能力上表現突出,尤其擅長文科任務。GLM-4-0520 的優異表現不僅彰顯了其研發團隊的技術實力,也為 AI 在教育、文化創意等領域的應用提供了新的可能性。
關鍵能力比較:各有所長,仍有提升空間
在理科能力方面,中國頂級模型如 Qwen2-72B、AndesGPT 和山海大模型 4.0 的表現已經非常接近 GPT-4-Turbo-0409,均取得了 76 分的高分。然而,與 GPT-4o 的 81 分相比,仍有一定差距。這表明在高難度的數學推理和科學計算領域,中國模型還有進一步提升的空間。
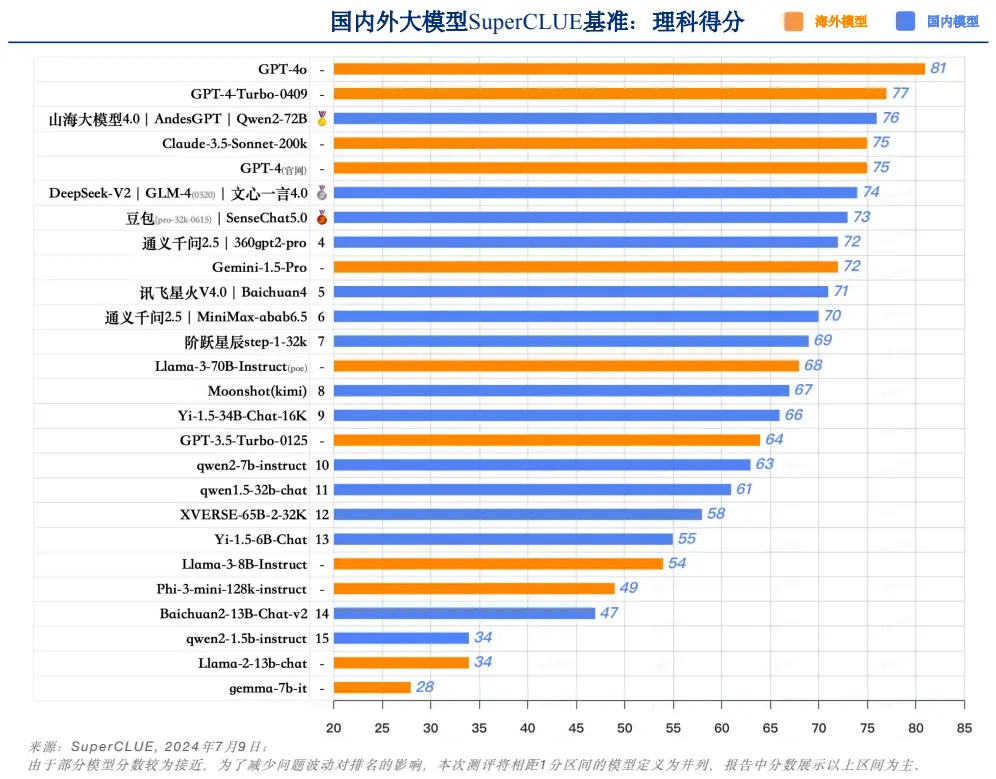
中文大模型基準榜單-理科得分。資料來源:SuperCLUE
文科能力方面,中國模型的表現更為亮眼。多個中國模型如 Qwen2-72B、AndesGPT、通義千問 2.5 和 DeepSeek-V2 在語言理解、知識百科和創意寫作等任務上均取得了與 GPT-4o 持平的 76 分。這一結果充分展示了中國大模型在處理語言和文化相關任務時的優秀能力。
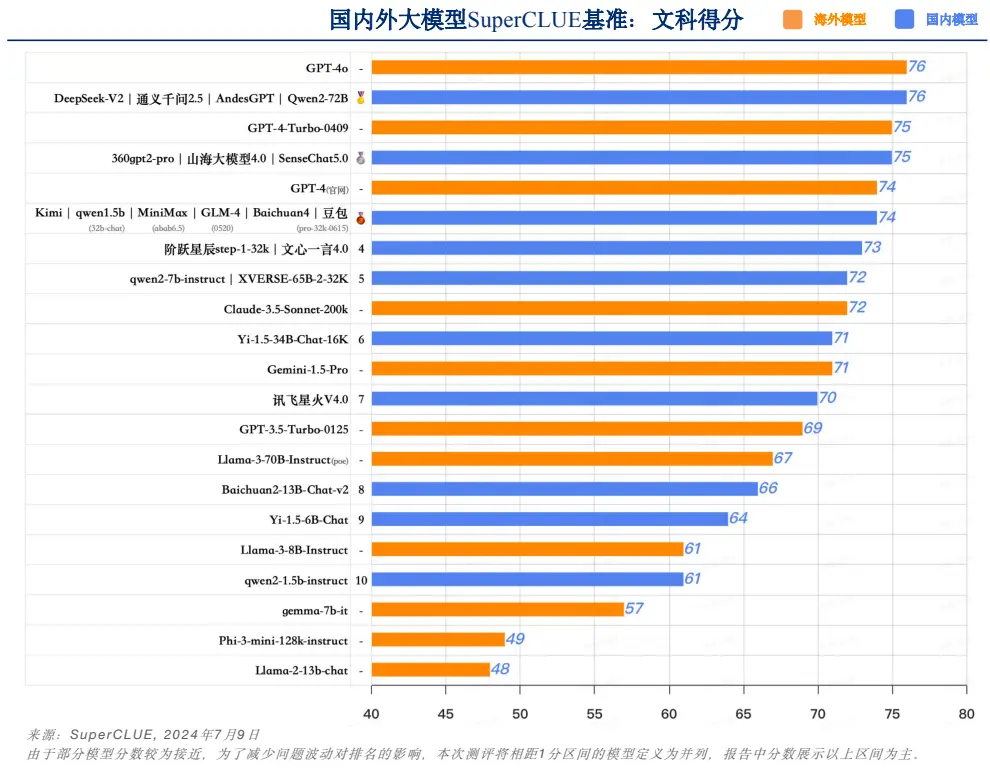
中文大模型基準榜單-文科得分。資料來源:SuperCLUE
在高難度任務中,尤其是精確指令遵循能力上,GPT-4o 和 Claude-3.5-Sonnet-200k 以 85 分和 84 分的高分領先群雄。國內表現最佳的 GLM-4-0520 和 Qwen2-72B 也取得了 79 分的好成績,但與國際頂尖水平仍有 6 分的差距。這個領域將是未來中國大模型重點突破的方向之一。
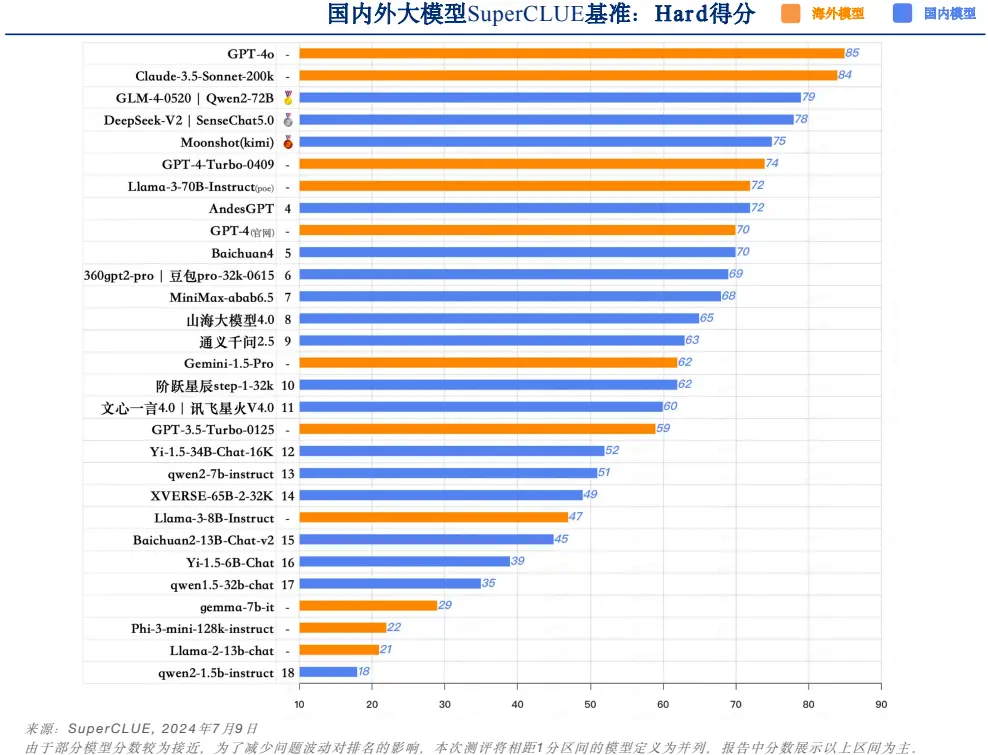
中文大模型基準榜單- Hard 得分。資料來源:SuperCLUE
行業應用潜力:AI 賦能垂直領域,創新應用指日可待
隨著大模型能力的不斷提升,其在各行各業的應用前景也愈發廣闊。根據 SuperCLUE 的評測結果,中國領先的大模型在金融、醫療、汽車等垂直領域已經展現出強大的應用潛力。
例如,在金融領域,Baichuan3、GLM-4 與 MoonShot-v1-128k 等模型的表現優於 GPT-4,顯示出中國大模型在處理複雜金融數據和風險分析方面的優勢。在醫療健康領域,多個中國模型在醫學知識理解和診斷輔助方面的能力也不容小覷,為 AI 輔助診療和個性化醫療的發展提供了有力支撐。
汽車行業是另一個 AI 應用的熱點。SuperCLUE 的評測顯示,多個中國大模型在車輛使用指南、故障診斷等實用場景中表現優異,為智能座艙和車載助手的發展奠定了基礎。
值得一提的是,AI 智能體(Agent)和多模態能力正成為大模型發展的新方向。中國一些領先模型在任務規劃、工具使用等 Agent 核心能力上已經接近或超過 GPT-3.5 的水平。同時,視頻生成、圖像理解等多模態任務也成為各大模型競相發力的重點領域。
機遇與挑戰並存,中國 AI 蓄勢待發
中國大模型的發展趨勢可謂機遇與挑戰並存。一方面在某些領域已經展現出與國際頂尖大模型抗衡的實力,特別是在中文處理和特定垂直領域的應用上甚至略勝一籌。另一方面,在基礎研究和極限任務處理能力上,與 GPT-4 等頂級模型相比仍有差距。
為縮小這一差距,中國 AI 企業和研究機構正在採取多管齊下的策略:
- 持續投入基礎研究,提升模型的底層架構和訓練方法。
- 擴大數據規模和提高數據質量,特別是在中文和多語言語料庫方面。
- 加強產學研合作,促進理論創新與實際應用的結合。
- 大力發展開源生態,吸引全球開發者參與,加速技術迭代。
- 聚焦垂直領域應用,在特定行業形成差異化競爭優勢。
結語
2024 年 6 月的中文大模型排行榜不僅展示了中國 AI 產業的蓬勃發展,也為未來的競爭指明了方向。隨著技術的不斷進步和應用場景的不斷拓展,中國大模型有望在全球 AI 舞台上扮演越來越重要的角色。在這場 AI 競賽中,中國企業正以驚人的速度追趕國際巨頭,同時也在開闢屬於自己的創新道路。